
江行智能DyGRO-VLA破解VLA模型“多任务困境”,点亮物理 AI 电力场景
江行智能DyGRO-VLA破解VLA模型“多任务困境”,点亮物理 AI 电力场景
当机器人学会一个任务后,往往会忘记之前学会的另一个任务——这是多任务学习中长期困扰业界的“灾难性遗忘”难题。如今,江行智能给出了一种全新的解法。
近日,江行智能研究团队在具身智能领域取得重要突破。研究成果 DyGRO-VLA 被国际机器学习顶级会议 ICML 2026 收录。该工作针对视觉-语言-动作(VLA)模型在多任务场景下的性能退化问题,提出了一种创新的两阶段优化框架,在LIBERO多任务操作基准上取得了平均成功率97.1%的优异成绩。

一、一个根本性困境:VLA模型“学得越多,忘得越快”
VLA(Vision-Language-Action)模型被视为通用机器人的核心范式。它将视觉感知、语言理解与动作控制统一到一个端到端模型中,让机器人能够直接理解自然语言指令并自主执行复杂操作。
然而,一个长期困扰业界的难题是:当VLA模型从单一任务扩展到多任务时,性能会急剧下降。
传统强化学习(RL)优化器在单任务上表现优异,但在多任务场景下,不同任务的梯度会相互冲突,导致模型“顾此失彼”——学会了一个新任务,却忘记了之前掌握的能力。这种现象被称为灾难性遗忘。
江行智能研究团队的深入分析发现,这种失败模式的根源在于:RL优化器会扭曲预训练阶段学到的共享表征,使得不同任务的经验被孤立,跨任务知识共享能力大幅削弱。因此,如何在控制精度与跨任务泛化之间取得平衡,成为VLA模型走向规模化应用的关键挑战。
二、江行智能物理 AI 技术突破:DyGRO‑VLA 两阶段优化框架
针对上述挑战,江行智能提出了 DyGRO-VLA(Dynamic Grouped Residual Optimization)框架,采用“离线预训练 + 在线微调”的两阶段范式。
第一阶段:信息瓶颈表征学习
在离线预训练阶段,DyGRO-VLA基于信息瓶颈(Information Bottleneck)原理,从海量多模态数据中提取跨任务共享的潜在表征。这些表征只保留对动作预测最关键的信息(如物体空间位置、形态特征),而过滤掉背景、光照等干扰因素。
这一设计的精妙之处在于:通过最大化表征与动作之间的互信息、同时最小化表征与原始观测之间的互信息,模型学会了“抓大放小”——只记住对完成任务真正重要的东西,从而使得不同任务的知识可以被有效复用。
第二阶段:混合残差强化学习(MoRR)
在在线微调阶段,DyGRO-VLA冻结了预训练好的共享表征,并引入混合专家残差策略(Mixture-of-RL-Residuals, MoRR)。
具体而言,MoRR包含三个关键设计:
● 专家池:一组轻量级的残差策略网络,每个专家只专注于优化某一类任务;
● 动态路由网络:根据当前任务的语义特征,智能地选择并组合最合适的专家输出;
● 残差学习机制:每个专家只输出对基础策略的“微调修正”,而非从头学习,从而保留基础模型的通用能力。
这种设计的核心优势在于:既保留了基础模型的通用能力,又实现了对特定任务的精准优化,有效避免了多任务RL优化中的灾难性遗忘问题。
三、实证成果:LIBERO基准测试平均成功率97.1%
DyGRO-VLA在业界公认的LIBERO多任务操作基准测试中进行了全面评估。该基准包含130个任务,覆盖空间泛化、物体泛化、目标操作和长时程任务四大套件。
实验结果表明:
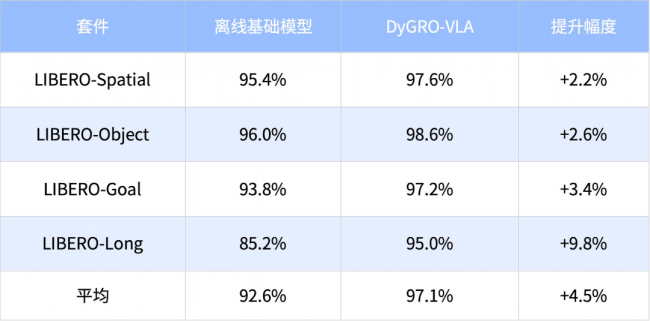
尤其值得关注的是,在最具挑战性的LIBERO-Long长时程任务套件中,DyGRO-VLA的成功率从85.2%跃升至95.0%,提升幅度高达9.8个百分点。这表明该框架在复杂、多步骤的工业级任务中具有显著优势。
在RoboTwin2双机械臂基准测试中,DyGRO-VLA在仿真环境取得79.2% 的最佳综合成功率,并在Sim2Real迁移测试中,在复杂双臂操作任务上全面超越现有基线方法。
四、工业价值落地:江行智能物理 AI 赋能电力场景与智能巡检
DyGRO-VLA所代表的跨任务强化学习框架,为江行智能构建一脑多体的工业智能中枢提供了关键算法基础。
在真实的工业场景中,一个AI系统往往需要同时应对巡检、操作、诊断等多种不同类型的任务。DyGRO-VLA验证了:未来的工业AI系统必须具备跨任务知识复用与高效扩展的能力,才能以可控成本实现规模化部署。
我们交付的不是一个只会做一件事的专用模型,而是一个能够持续学习、不断扩展的通用智能底座。
相关研究:
DyGRO-VLA: Cross-Task Scaling of Vision-Language-Action Models via Dynamic Grouped Residual Optimization. ICML 2026.
江行智能将持续深耕物理AI前沿技术,让AI更好地理解、适应并赋能我们所在的真实世界。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。











